


Do the problems with election polls doom issue polling too?
Reanalyses of 2020 polling data suggest that surveys about political attitudes are probably more accurate than pre-election polls


Robert Shapiro, a Columbia University professor and scholar of public opinion (among other things), wrote a piece for the Monkey Cage political science blog at the Washington Post yesterday that says:
In 2020, polls appear to have overconfidently predicted that Joe Biden would handily defeat incumbent President Trump.
While researchers are sorting out the final numbers, some observers are arguing that polling has outlived its usefulness. But while pre-election polls have their problems, mass opinion polling is quite different.
Pollsters frequently make this argument, especially after elections they get wrong.[1] And while most people believe the only real benchmark of political polling is the results of the election, there is both (a) a long history of research into surveys as well as (b) other contemporary data that shores up our faith in broader public opinion polls.
Editor’s Note: This is a paid post for premium subscribers. If you are a subscriber and have friends or family that you think might learn something from this post, you should feel open to forward it to them regardless of their membership status — but please also encourage them to sign up for posts themselves by clicking the button below!
Also: it’s that time of year again!🎄The holiday season usually produces a big chunk of my yearly subscription numbers. I would be grateful if you would consider sharing the link to this newsletter on social media or giving a gift subscription to a family member or friend who might keep it going in the new year. As a reminder, your support not only gets you access to premium content (like this email!) but also makes a huge difference to me personally and makes this entire endeavour possible.
Here’s a bit more of Shapiro’s analysis and his argument (which I wanted you to read so badly that I simply copy + pasted it into this email):
Crucial state polls were significantly off once again, especially in Michigan, Wisconsin and Pennsylvania. Yes, Biden won these states. But he did so by thinner margins than were found in pre-election polling results, which steadily forecast him winning by 4 to 5 percentage points or more. Further, Trump defeated Biden in states that were allegedly close, like Florida and Texas, by handier margins than expected. In Arizona and Georgia, the polls were within sampling error margins. But they were way off on several congressional races. Maine’s Republican Sen. Susan Collins won handily, despite pre-election polls showing her opponent leading. And while some expected a “blue wave” election that increased Democrats’ control of the House, Republicans gained House seats.
What went wrong? For one, polling was conducted during the pandemic. Many states were voting early or by mail in large numbers for the first time. They then had to count these votes under crisis conditions for voters, Postal Service, and state elections administrators. Disproportionately Democratic poll respondents reported that they were going to vote by mail; some may have failed to do so, ran into difficulties, or had their ballots lost in the mail, contributing to polling error.
But here’s the challenge for pollsters: knowing who will actually vote compared with who is responding to polls. Pollsters have to estimate the composition of “likely voters,” based on what’s happened in the past, then accurately weight respondents’ answers for comparable demographic characteristics.
The AAPOR convened a new task force, like the one it had in 2016, to examine 2020 pre-election polling. Its postmortem forensics will need to use voter file data to check the survey estimates of likely voters, to see how pollsters underestimated turnout supporting Trump.
It will need to consider the same potential problems discussed during 2016. These include whether some respondents were “shy Trump voters,” reluctant to disclose their intentions, or whether Trump voters were less likely to respond to polls, which pollsters call “nonresponse bias.” This may not have just meant underestimating the number of Whites without college degrees who were likely to vote, but also underestimating likely voters in rural or small-town areas, who voted overwhelmingly for Trump.
The 2020 National Election Pool’s exit poll found roughly the same percentage of Democrats (37) and Republicans (36) had voted, with comparable percentages or more Republicans in key states. Pre-election polls often identified greater proportions of Democrats than Republicans as likely voters.
Then, Shapiro gets to the crux of his argument:
None of that affects public opinion polling, which is quite different
But while election polling definitely has problems that need to be studied, some pundits are claiming that public opinion polling has failed entirely. That’s not so. Mass opinion polling is a very different animal from election forecasting polls. It occurs regularly between elections, examining all manner of political and social attitudes and behaviors. And it’s reliable and useful for political scientists and others who study U.S. democracy.
So what’s the difference? In pre-election polls, pollsters must estimate who will vote. In mass public opinion polls, pollsters don’t have that problem. Survey samples can be effectively weighted to match census data about the entire adult U.S. population and its subgroups, drawing on an enormous research literature on trends and patterns in public opinion, including partisan conflict today.
These polls can be benchmarked against high-quality government agency surveys, which have high response rates and draw on large samples. They can also be checked against similarly high-quality academic surveys, especially the NORC General Social Survey and the American National Election Studies.
As someone who has been reading a ton of old AAPOR reports and histories on polling misfires over the last few months, I think that there is more truth in this argument than some analysts are giving Shapiro credit for. Nate Silver, for example, tweeted this in response to the article:
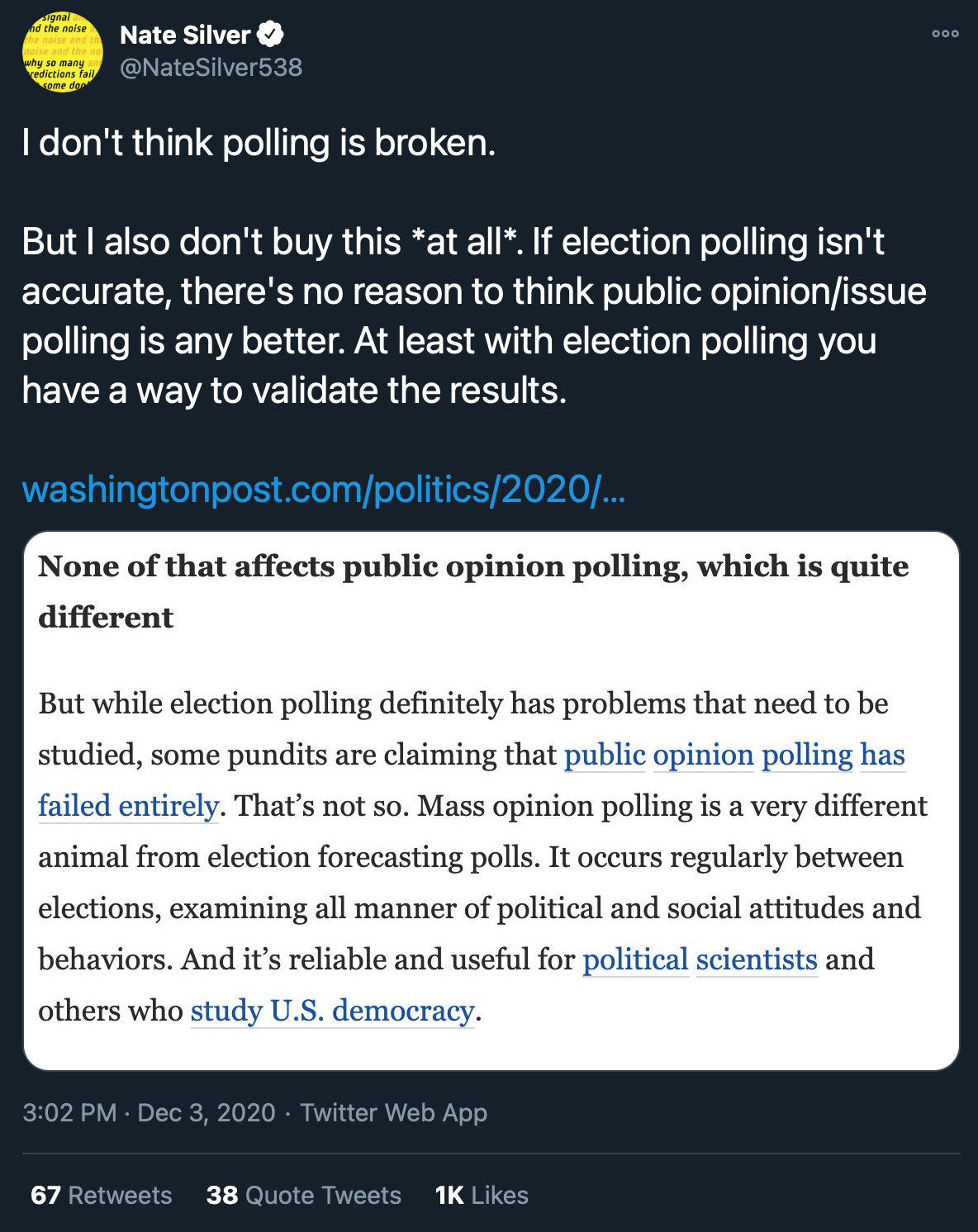
There is both truth and misdirection in this tweet. On the one hand, yes, pre-election polling provides the best benchmark of the performance of political polls. If they miss the election result by four or five points, then the topline attitudinal data — “do you favor or oppose closing restaurants to prevent the spread of covid-19,” for example — are also probably off too.
But the statement “if election polling isn’t accurate, there’s no reason to think to think public opinion/issue polling is any better” really overlooks some emerging information on the subject.[2] It might technically be right in a vacuum, but it ignores important context from other analyses of both past polls and data from this year.
At this point, I have heard from several pollsters (all of whom wanted to be off the record until they publish their own analyses, so I don’t scoop them) that re-weighting their data to match the national presidential election results only changes their toplines on covid and other politically charged issues by 1-3 points. For reference, these pollsters are all highly rated and missed the national vote by much more than 1-3 points. (This also means that the pro-Trump biases in the aggregates of attitudinal data, could be even lower than 1-3% since the average of all polls performed better than did the pollsters who have gotten back to me on this subject.)
So, what explains the difference between the performance of pre-election (“trial-heat”) and opinion polls?
First, the traditional argument from pollsters that issue polls are immune to variance from trying to get a good likely voter filter (considered the main source of potential error in pre-election polls historically) is probably right. We know that some likely voter filters have performed better than others in the past, which implies that prediction voters’ actual behavior (rather than their attitudes — ie whether they’ll vote versus who they’ll support if they do) is a real extra source of error for the polls. I don’t really get why Nate is arguing otherwise; the research is pretty sound here.[1]
Second, we should expect that the response items (what pollsters call the individual things you have an opinion on — who you’re going to vote for, whether you approve of Trump, etc) that have a higher correlation to (not) picking up the phone would suffer more from potential partisan non-response bias than other questions. If some underlying trait makes you both (a) less likely to complete a phone poll and (b) less likely to approve of Trump’s handling of the coronavirus, in ways that pollsters can’t adjust for using typical demographic and political weighting, then we would expect polls to underestimate support for the president on the coronavirus.
As it turns out, the evidence suggests that the correlation between non-response and Trump support is higher than the correlation between Trump support and, say, covid restrictions etc. That’s pretty reassuring! It suggests that the past evidence of overall public opinion polls taken among registered voters or all adults are probably less biased than pre-election surveys of likely voters.
In sum, despite what some analysts are arguing, the data we have do actually suggest that issue polls could be better off than pre-election polls — an idea that fits with a long history of research on this subject.
Notes:
[1] I can’t help but think that many pollsters are trying to have their cake and eat it too — using good pre-election numbers to argue that their data are good but saying “oh issue polls are actually fine” when their election snapshots go wrong. Some pollsters have acknowledged this and said they’ll try to do better, but this has probably already produced an overall communicative weakness for the industry that will be hard to fix.
A related problem is when pollsters (and election forecasters) cheerlead for themselves by saying they “called” x number of contests correctly. This is bad because it feeds a very damaging myth about how polls work that is more often used to attack the industry than support it.
[2] Here are two related points about Nate’s criticism.
First, Silver’s media outlet makes a huge chunk of $$$ during the election year. Maybe FiveThirtyEight could use some of those funds to field a poll and conduct these analyses too? To test the effects of weighting by Trump support on other response options? They have partnered with Ipsos in the past so this isn’t a far-fetched idea or anything. It could be very insightful, and as a bonus would certainly be much more productive than just speculating about the matter on Twitter.
Second, his argument seems to be weirdly unempirical for someone whose website says they use “statistical analysis — hard facts” to answer questions about politics. Maybe this is a simple case of a human getting caught up in defending a position that they have already publicly committed to in order to not appear wrong.
I'm still waiting for someone to figure out who these people are who actually answer their phones when they have no idea who's calling. I keep asking people if they ever talk to unknown numbers and not a person says they do...they just immediately block them.
What is the psych profile of somebody who is so bored or naive that they answer every unknown call even though the vast majority are spam? I doubt that there is a group of people who are so committed to answering pollster's questions that they will endure any number of spam calls until they hit the jackpot.
In other words, there's got to be another reason they'll do this and I'd like to know what it is because it is certainly skewing responses in some fashion.
I've heard Ann Selzer claim that, in lieu of using a pollster-applied likely voter screen they just ask respondents whether they are likely to vote and believe them. Selzer nailed Iowa -- FWIW.