


Saturday subscribers-only post: Extras from a lecture on the future of polling and election forecasting
I was in Salt Lake City this week to promote my book — which will soon be available for pre-orders!

I know it's way too early to start thinking about 2024 (or even 2022), but it's never too early to start promoting my book. And so I was very excited to be invited to Salt Lake City this week to give two lectures on polling and forecasting to students at the University of Utah, and to talk more generally with political science graduate students about applied statistics and data science.
And to be totally honest, things were going really well until one of them asked me:
Aren't election forecasts just pointless, then? If polls are subject to so much unpredictable error, are we better off just communicating about them in a different way? Or not doing them altogether?
I was a little caught off guard. For starters, asking someone if the thing they work on is “pointless” is not likely to elicit an immediate and good response! But after I thought for a second, I realized the student's comments teed up all my thinking about polling and forecasting almost too well. And though I was a little bothered by the implication of the question (which I'll get to in a second) I think it set us off on a pretty decent conversation on the subject.
So, to answer the question: Election forecasting models (or, as I've come to prefer calling them, "polling models") are definitely not pointless. At a basic level, simulating different outcomes according to the historical uncertainty around a polling average gives audiences a dramatically improved picture of what the polls are saying about elections and how much you can trust them. There are things I think we forecasters do wrong — forecasting from excessive time horizons or focusing too much (or really at all) on probabilities, for example — but aggregation and forecasting have dramatically improved how the media covers polls, in my opinion. In fact, given that polls are subject to so much extra error than people typically understand, exploring that error with a model is probably more important for good data-driven journalism, not less.
That's a pretty easy thing to explain, I think. The value of the model is in explaining something that otherwise wouldn't get explained at all! But the implication that forecasts have to be perfectly accurate to be useful surprised me — mostly because I had just spent a whole hour explaining how our expectations for the polls are too high, and how they can offer information to legislators without being within one percentage point of the outcomes, even though that's what people want from the prognosticators.
But I was really excited that he asked about better ways of communication. Among many other things, the 2020 election showed me that readers are really bad at ingesting ranges of outcomes from our models. For example, even though the charts from The Economist and FiveThirtyEight (among others) prominently showed the scenario in which a larger-than-average polling error caused Biden to win 306 electoral votes instead of the ~330 at his median forecast, people were still dramatically surprised by the outcome. And one reason for this, I think, is because we told them a Trump win was such a low probability and showed the scenario where Biden won 306 EVs relative to all the other scenarios our model thought were more likely.
If uniform bias in the polls is becoming more common, however, showing potential outcomes alongside probabilities is probably giving people a skewed picture of reality. And the alternative of arbitrarily increasing uncertainty isn't the right move. So maybe it would be better to just show the election forecast conditional on different levels of polling error first, and hide the probabilities even lower down. That way forecasters highlight the potential uncertainty first.
One idea we came up with is to visually show what would happen to the median electoral vote forecast if the polls were off by one, two, three, etc. points in either direction. We could also provide the added context of showing what a 2016-level or 2008-level error in the polls would mean this time around. Though the New York Times did this in a table last year, I think a visualization could be even more powerful. Here's one way we thought about showing these conditional predictions:
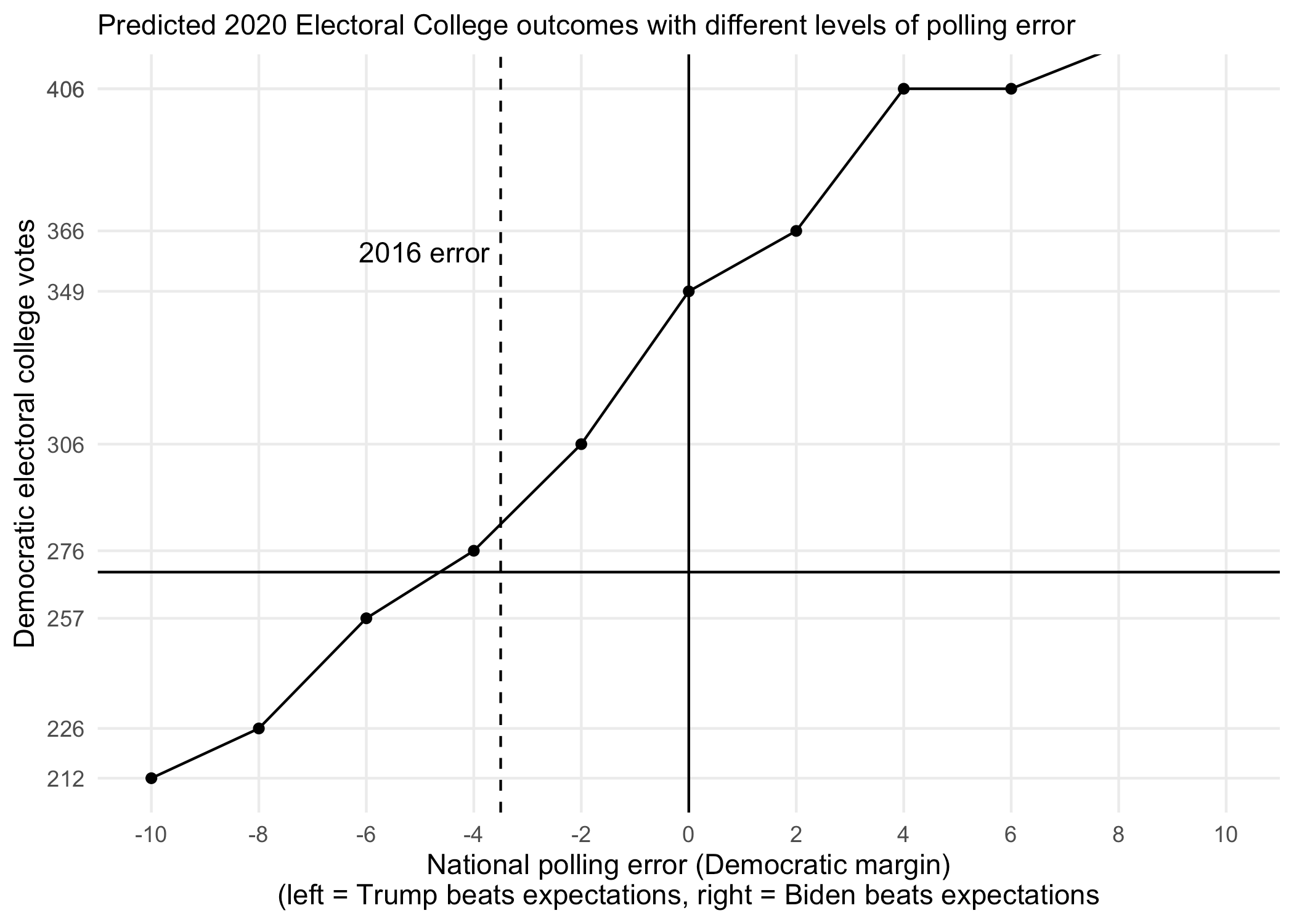
So, that's it. I think the future of (public) polling models lies not in the pursuit of laser-like precision, perhaps from using machine learning models with polling microdata and administrative records or some such (though there are some methodological improvements we will make to our model by 2024), but rather in investing much more in the communication of our models and the uncertainty that comes with them — particularly before we prime people with expectations for binary events.
That's it for this week's subscribers-only post. I hope you all have a great rest of your weekend. My plane returning from SLC will touch down in the Washington area shortly — and though I am sure I'll miss the sunny, cool weather of the West once it does, it is always a relief to be back home.
Oh, and PS: If you're a faculty member who wants me to give a talk about polling and forecasting, please get in touch. I really love talking to students about applied statistics and data science — even outside of the context of poll and politics!
Elliott
Hi Elliott,
I believe we discussed this before, my big issue is how the media covers polls and forecasting models. If readers/viewers understood polling error, they could have a higher level of trust of models and polls. Rebuilding that trust would be good, especially for non-election polls.
While this would require a lot more work, I wonder if models could include a few Electoral College maps to illustrate polling error. There could be five different maps: the traditional model, two normal sized polling error maps (errors favoring each candidate), and two larger than normal sized polling error maps. I wonder how people would react if they saw the range of outcomes in a visual manner. If models were showing maps where Trump was winning and where Biden was winning big, would that help people understand polling error? For 2020, I would've wanted people see a map where Trump won all the states he won in 2016, plus NV and a map where Biden won 413 Electoral Votes with a TX win.
I found an article that Dave Wasserman wrote in 2016 very helpful. Going over five scenarios showing five different maps helped me visualize the range of outcomes. This is a possible solution to communicate more effectively.
You’ll Likely Be Reading One Of These 5 Articles The Day After The Election
https://fivethirtyeight.com/features/youll-likely-be-reading-one-of-these-5-articles-the-day-after-the-election/
We also need more of these articles.
Trump Is Just A Normal Polling Error Behind Clinton
https://fivethirtyeight.com/features/trump-is-just-a-normal-polling-error-behind-clinton/
Trump Can Still Win, But The Polls Would Have To Be Off By Way More Than In 2016
https://fivethirtyeight.com/features/trump-can-still-win-but-the-polls-would-have-to-be-off-by-way-more-than-in-2016/
I'm looking forward to reading your book!
-Elliot
Book, over here, please.