


Media coverage of California's recall election highlights big issues with popular poll aggregation models
Polling has gotten more complicated. Models will have to adjust to work properly.


When I was a kid we had this dusty, boxy, grey television in our dark, carpeted living room. We didn’t grow up with satellite or cable so we’d spend a lot of time searching for public access programming — PBS’s NOVA series of science documentaries, mostly — that wasn’t obscured by a fuzzy mess of black and white noise. Frustrated, we’d get up to reposition the digital antenna we used to pipe signals in from the local television station. If that didn’t work, we would resort to the most scientific of methods: slapping the side of the TV with our open palms. That usually did the trick.
On poll-averaging, I think it’s time we slap the TV. The rough outlines of the image are coming through, but methods need a bump to lock on to the signal again.
The chart below is FiveThirtyEight’s average of polls for today’s recall election in California, where governor Gavin Newsom faces a challenge from right-wing activists to remove him from power. (He is very likely to win the recall and stay in power.) The blue line represents the share of California voters who want to keep Newsom as their governor; red, remove:
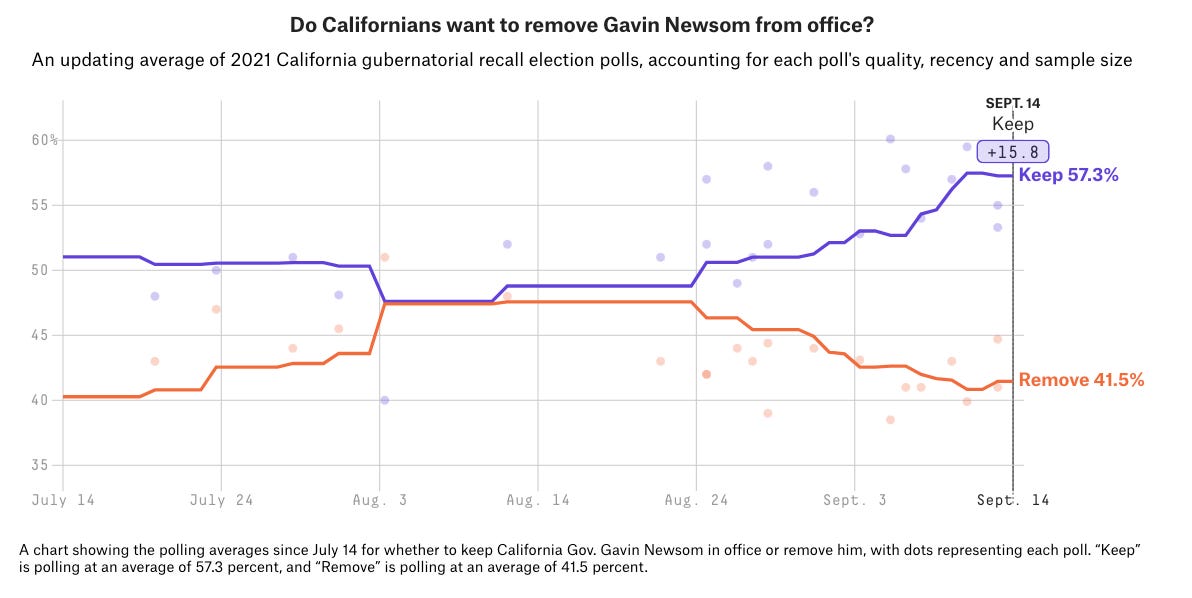
This chart tells a compelling story, doesn’t it? The governor of California, elected in 2018 with 62% of the vote, was earlier in danger of being recalled from office (he must receive a majority of votes in the election to survive). In August, he may have even been trailing. But he has since pulled ahead in a massive swing of support for his campaign.
Or maybe the signal line is too noisy.
I. Make sure you’re on the right channel
Take a look at the two vertical dots on August 4th. They show the results of a poll conducted by SurveyUSA, a public opinion pollster and market research company that has been around for decades. Their election survey that day revealed only 40% of Californians wanted to keep Newsom as their governor, versus 51% who would vote to recall if the election were held tomorrow. To date, it is the only poll from a major firm to show Newsom losing the campaign.
There’s just one problem. It was likely a fluke. The result was driven by poor question-wording — it was not an accurate measure of public opinion. It was noise. And that’s not my analysis, the pollster itself has admitted this!
Twenty-seven days after SurveyUSA released their “SHOCK POLL” (as one outlet called it), the firm posted the results of a new survey showing Newsom with an eight-point lead over the recall campaign, 51 to 43 (or roughly 54% of the vote after allocating undecideds proportionally). They took a few paragraphs to explain what had changed. It wasn’t the race, in summary, but the wording they used to identify a likely voter. Via an artifact of their original wording, they had inadvertently excluded many voters who were opposed to the recall from the pool of “likely voters” and titled the campaign against the governor. Here it is in their own words:
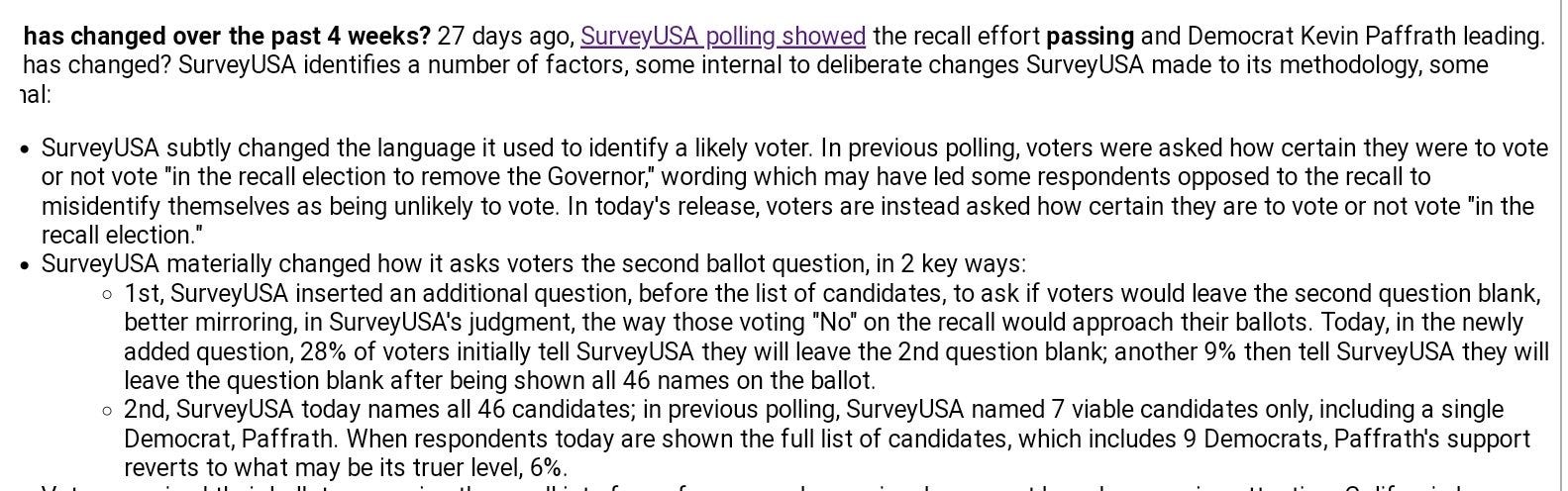
This is as close as you get to a public pollster disavowing their own work. Admitting that the results were caused by a fluke in question-wording is common, of course. (Flukes are the most common fish in the sea; if you go fishing, odds are, you’ll catch one.)
But rarely are impacts this large. Rarer still do they impact the very historical narrative of the campaign. After SurveyUSA posted their first poll, Democrats sent out a fundraising email with an ominous warning:
“THIS RECALL IS CLOSE. Close enough to start thinking about what it’d be like if we had a Republican Governor in California. Sorry to put the thought in your head, but it’s true.”
Conventional wisdom about the race also changed. The odds that Newsom would be recalled on PredictIt.com, a betting site, reached their all-time peak the day after the poll was released.
Subscribe for more
I send out one weekly blog post to free subscribers each Sunday recounting the week in polls, public opinion, and political science. You’ll also get updates on my work and reading list. Paying subscribers ($5/month) receive 1-2 extra posts on the same subject each week.
This was initially a subscribers-only post, but I have ungated it in the public’s interest.
In one big sign of media miscalibration, these myths persisted even after SurveyUSA had posted their retraction. On September 7th, Galen Druke, the producer of FiveThirtyEight’s weekly politics podcast, asked a panel of guests “Given how close the polls were weeks ago, days ago, how would you described the competitiveness of the recall?” Paul Mitchell, the CEO of Political Data Inc, responded by saying the closeness of the race was a mirage:
“What I think we saw a few weeks ago was a couple polls, first the Berkeley IGS poll… was showing among a likely electorate, self-defined … that this thing gets close. But with that kind of electorate you’re assuming about 35% of the electorate when they’re really only 24% of registered voters.”
That is the same error that caused the fluke SurveyUSA poll.
And based on his analysis of which California voters were returning their ballots, he concluded:
“We’re looking at a high turnout election based on what has come in already and this doesn’t look like the type of election where Republicans are really gonna surprise the governor and have overwhelming enthusiasm that creates a skewed electorate.”
In response, Nate Silver said:
“One thing to keep in mind is this is not a presidential race where you have seven polls coming out every day. We’ve had a decent volume, but it’s enough where individual polls can swing our average and public perceptions by quite a bit. And this SurveyUSA poll in early August… That kind of swung the numbers a lot.
But kind of like what Paul was getting at, you had polls with differences between registered and likely voters that were generally implausible. [But these SurveyUSA and Berkeley] polls showed a double-digit gap [between the Republican share of the registered and likely voter electorate] that was always a little bit implausible.”
He finished:
“I think if you get that result you really fucked up your likely voter screen. It’s not a plausible result.”
Laurel Rosenhall a reporter for CalMatters, said in response:
“That was a massive outlier in months and months of polling that was the only one that showed the recall winning. [….] That did change the narrative, and it also changed the average and lots of people look at the average you guys do and so that contributes to the public understanding of it. But then SurveyUSA came out with a memo explaining a lot of big problems with that poll that could have led to that result.”
Nate Silver replied:
“In general we talk about polls as outliers as … statistically a couple of standard deviations away from whatever the average of polls is. That could happen and does happen because of randomness… it can happen because there is a real shift of the race. It usually doesn’t mean that there was something wrong with the poll. So when the pollster comes out with a memo showing here’s how things got misinterpreted, that’s worth paying attention to. Empirically, people don’t have a good sense of when a poll is a true outlier in a sense of being a mistake.
The SurveyUSA poll was so not replicated by any poll before or afterward… the fact that it couldn’t be replicated is not great.”
This begs the question, of course, why keep it in the average? FiveThirtyEight has provided a generally subpar answer in response. The site’s political reporter Nathaniel Rakich told me:
“Our polling averages are meant to be descriptive, to reflect all (non-fake) polling that’s been released—warts and all.”
But this is no wart! It is a data processing error — and a large and consequential one at that. Just take a look at what the FiveThirtyEight average would look like if they had removed the SurveyUSA poll, or exercised discretion and never added it in the first place. (Chart courtesy of Mr Rakich.)
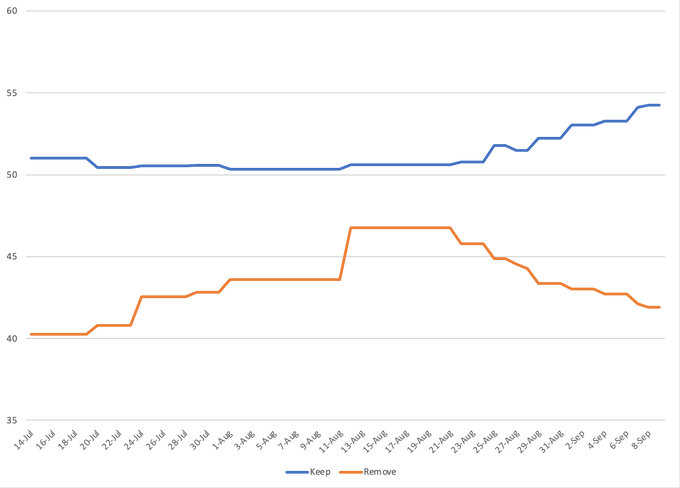
The signal and the noise, indeed.
II. Slap the TV!
So one issue with FiveThirtyEight’s aggregation model is that it is pulled around too wildly by clear outliers that, by the company’s admission, are “fucked up”. They could do two things to address this issue: First, they could exercise more discretion when adding data to their models. Perhaps they don’t add “fucked up” data at all, or they give it a lower weight to provide ad-hoc adjustment before seeing more information.
But 538 could also design aggregation models that aren’t so reactive to clear outliers. You can do this with more sophisticated Bayesian techniques than the ones 538 already uses; perhaps, like The Economist did in 2020, by modelling the race as a mean-reverting trend that gets updated by polls using a much larger standard deviation than is commonly assumed. This means that individual polls have a smaller impact on the trend when they’re further away from other surveys.
Since we think the margin of error for surveys is roughly 2-3x what pollsters typically report as the total “sampling error” of a poll, this is an appropriate adjustment. The SurveyUSA case proves that other things — such as question-wording, but also which variables you weight on and how you do so — can pull the results of a poll over a wider range of outcomes. So instead of the SurveyUSA poll moving the average by seven points, it only moves it by 2 or 3. Although increasing the measurement error of the data going into the model will decrease the aggressiveness of the underlying trend line, the precise parameters can be tuned to still preserve a quickly moving aggregate by election day.
If you’re liking this post so far, please share it on social media so other people will see it.
One other big issue is that the FiveThirtyEight model doesn’t know anything about how the data were collected or processed. In both the case of the California aggregate and for their general election trends, their underlying aggregation models are blind to the weighting variables each poll is using. But in most cases, the including variables provide bias reduction in predictable ways. Weighting your polls by the share of non-college whites in the electorate would have increased Republican vote share in 2016 and 2020, for example; omitting race could have similarly inflated shares for them.
The biggest factor here is the shifting patterns in the partisan balance of the poll. Having too many Republicans or Democrats in your sample can cause artificial shifts in the toplines of the data. These patterns of differential partisan non-response make polls reflect more of who is getting surveyed, rather than what all (likely) voters in a jurisdiction are going to vote for. If the underlying share of Democrats or Republicans isn’t actually changing as your poll indicates, we’d considered that added bias. This is one of the problems with the SurveyUSA poll, but also with other polls of the recall.
If you don’t have access to the underlying polling data to re-weight the results yourself, one thing you can do is include this information in your aggregation model and adjust for it yourself. You would tell the computer to draw a trend line through the data and calculate the residual difference between the trend and each poll based on whether it was weighted to be representative of the population by party registration, identification or past vote. I’ve done that in a model linked here. The model also allocates undecided voters, who tend to gravitate towards the dominant party in a state. These are the results:
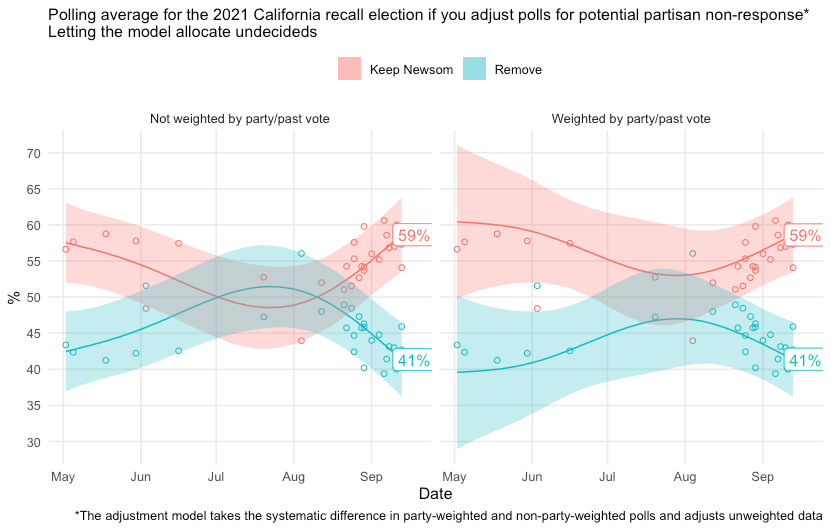
The two panels show two polling aggregates: one, on the left, which shows conditional results as if all polls were conducted without being weighted by political party; and another that shows the adjusted trend. Note the differences in initial level, but also in trend. Average recall vote intention in the party-weighted trend is much flatter, as we’d expect for polls that remain balanced by party over time. This all in just 52 lines of code (which I have made public!), and well within the statistical capabilities of the folks at 538.
III. Buy a new flat screen
The technology of televisions has evolved rapidly over the last 20 years. The boxy “rear-projection” televisions of my childhood have been replaced by flat-screen and LED technology. Things have changed significantly even since FiveThirtyEight was founded in 2008.
Polling has also changed. Response rates are lower now than they were then. Partisan non-response is much higher, and the swings from poll to poll — at least for pollsters who put more weight on random sampling and use simple models with traditional technologies like overfit raking algorithms — have gotten larger. The models of that data will need to adapt to the times.
The errors with FiveThirtyEight’s model of the California recall election have illustrated a point long apparent to consumers of polling averages: Popular averages magnify unlikely trends in public opinion by being whipsawed by data that is subject to higher standard errors than popularly realized, especially from partisan non-response. Weighting by party flattens trends by decreasing the topline effects of an artificially shifting electorate.
Adjusting for these factors is a no-brainer. Yes, it means political statisticians might have to apply more discretion when choosing which polls to include or how to adjust for them. But note I didn’t exclude any data here, I just let the model decide how to adjust for the flukes caught in the net. It also means the uncertainty of the aggregate (which is conspicuously missing from 538’s trends, despite their claims to be sensitive and conservative Bayesians) increases as we adjust for more factors. The uncertainty of a better model may seem so large as to make the aggregate useless, but that's a little silly. Instead, I think these intervals better represent the total survey error inherent in public opinion polls: a framework that most popular analysts of polling data have ignored for too long.
I think we can be much better stewards of polling data, so long as we are not blinded by the limitations of outdated methods and theories of pollsters’ data-generating processes. Hopefully, this post will point people in the right direction.