


Employment data come from surveys!
Government statistics suffer from significant processing noise and shifting patterns of nonresponse biases (just like political polls)

People who don’t answer surveys cause biases in the things they measure. The methods researchers use to adjust for those biases can add further noise to those estimates.
These are two important facts of survey sampling that people too often forget. In politics, they mean pre-election polls can miss the mark because the people picking up the phone (or logging in to the computer) are systematically different than those who aren’t. Weighting by too many variables — like age, race, education, participation and the interactions between those — can also cause higher variance in a polls.
But nonresponse and statistical flukes also affect the surveys the government conducts to gauge things like hiring, the unemployment rate and labor-force participation. Sometimes, the biases from these factors can even be quite large.
Take December’s job report. Based on interviews conducted by the Bureau of Labor Statistics, the government estimated that about 200,000 jobs were added each in November and December.
But then, when the January job report came out last week, the BLS reported substantially different estimates for its monthly change in non-farm payrolls. The new estimates put the number of jobs added in November and December at 600,000 and 500,000, respectively. What’s going on?
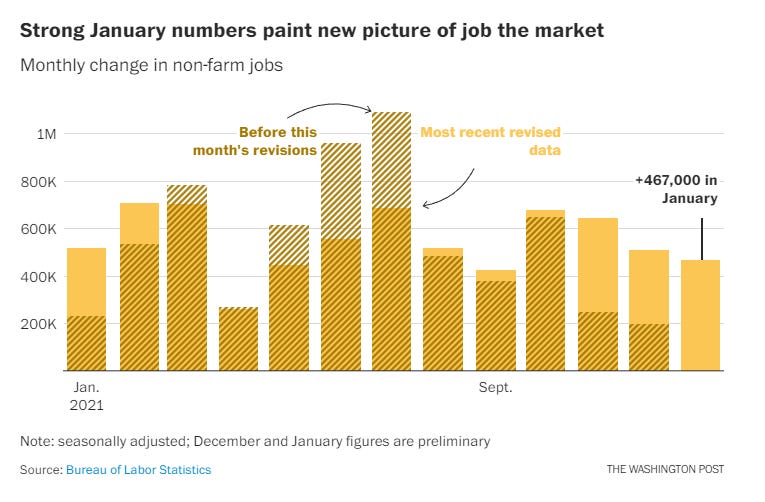
According to the BLS, the Current Employment Statistics (CES) survey samples about 140,000 business and government agencies each month. They survey large companies and small ones; retail and financial; south and north (and on and on). Firms are asked to provide data on the people on their payroll up to the most recent pay period. They have about two weeks to respond. Then, the government crunches the data on new payrolls, making seasonal adjustments to reflect typical surges and declines in hiring.
The BLS makes its initial jobs report based on these surveys, which are conducted in the first half of the month. However, it still receives responses from the other businesses; it adds these in the following month and provides revised estimates after adding them to their calculations. When something causes the groups of respondents to be different, you get large revisions. It’s possible that the surge in cases of the Omicron variant of covid-19 caused heightened nonresponse to the survey in the late fall/early winter of 2021 and threw estimates off.
Revisions also happen as part of an annual process of updating the bureau’s seasonal adjustment model. They take all the data in the past year and re-train their models which remove any predictable historical variation that may happen from seasonal hiring/iring cycles, etc. The BLS writes:
Now that there are more monthly observations related to the historically large job losses and gains seen in the pandemic-driven recession and recovery, the models can better distinguish normal seasonal movements from underlying trends. As a result, some large revisions to seasonally adjusted data occurred with the updated models; however, these monthly changes mostly offset each other. For example, the over-the-month employment change for November and December 2021 combined is 709,000 higher than previously reported, while the over-the-month employment change for June and July 2021 combined is 807,000 lower. Overall, the 2021 over-the-year change is 217,000 higher than previously reported. Going forward, the updated models should produce more reliable estimates of seasonal movements.
That is all for the estimates of job growth, which come from surveys of businesses.
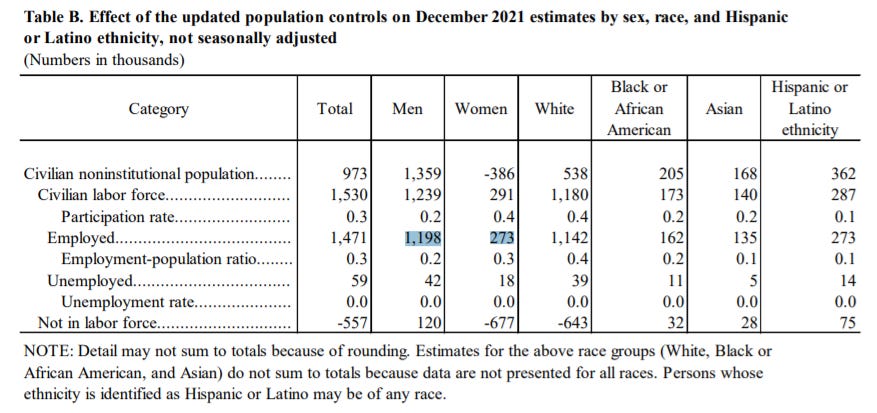
Finally, to offset nonresponse in the Household Survey, which measures things like labor force participation and unemployment, the BLS re-weights their raw data to a set of population characteristics that are measured by government surveys. This makes sure they have a set composition of the American population by race or gender. And these benchmarks are updated every year.
This can cause pronounced differences in the results of the Household Survey whenever new targets are released. When the BLS re-ran their numbers on December employment using the Census Bureau’s updated estimates, their prediction of the number of men in the labor force rose by 1.2m out of an estimated 1.5m increase in total jobs — causing an artificial drop in the female percentage of the labor force which some outlets reported as a million more men than women returning the labor force in January (Axios later corrected the story).
. . .
Now, I do not want to leave you with the impression that government data are bad or untrustworthy, or that they fail to reach a level worthy of instructing policy. Instead, what I want people to realize is that getting very precise estimates of important statistics is really hard! Modern adjustments to survey data can cause changes in estimates that are completely artificial, algorithms that are used to correct biases can change previous estimates when new data are considered, and nonresponse inside corporate or demographic strata can cause other random errors across surveys that cause journalists to emphasize phantom swings in quantities of interest — namely the unemployment rate among subgroups or new job starts in different industries. And none of these problems magically go away just by virtue of having huge sample sizes.
This is an argument for using survey data more cautiously. Acknowledging the process that generated government estimates might mean you have to wait until the BLS revises its job numbers before you form your narratives about politics, the economy, or what have you. It may mean our leaders are dealing with extra uncertainty in the policymaking process. But that sounds like a huge improvement over committing ourselves to a set of conclusions that could change next month simply because of random variation in who is taking surveys, plus non-random variation in the way they are conducted.
A lot of headache could be avoided if confidence intervals were part of the publicized #s. That’s a double-edged sword because of how people generally respond to uncertainty, but would help put point predictions in context
Good short article from a financial planner I follow regarding the superiority of American government data sets, especially when compared to other countries. https://www.pragcap.com/a-little-love-for-american-economic-data/